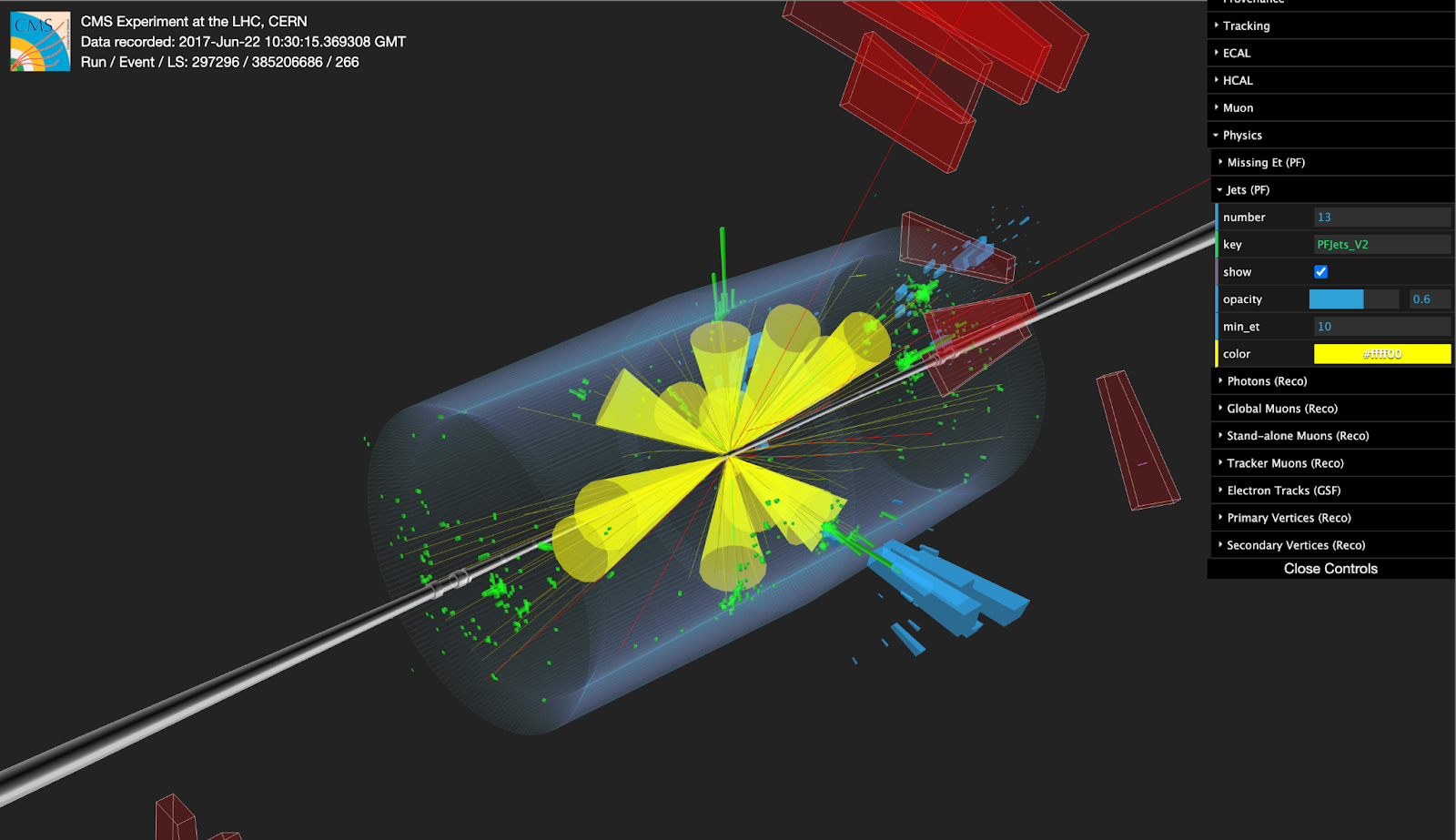
As part of the US-CMS PURSUE summer internship project, we hosted Xinyue Wu, a rising junior from the University of Rochester. The purpose of the internship is to provide a real research experience to undergrad students in topics related to the CMS particle detector of the Large Hadron Collider. Xinyue implemented a process to search for collision events of interest from real data provided by the CMS detector, and compared the results obtained to predicted yields as computed from simulation data. The events found were then visualized using tools provided by the CMS software environment.
For this project, Xinyue quickly learned how to use different technologies related to CMS analysis workflows running at scale in a distributed system. These included HTCondor, Coffea, TopCoffea, and Work Queue. Xinyue was able to run this analysis workflow using hundreds of cores at the University of Notre Dame compute nodes.
We thank Ph.D. candidate Kelci Mohrman and Prof. Kevin Lannon for their support and input. We congratulate Xinyue on the very successful completion of this project!