Grad student Barry Sly-Delgado presented his recent work on "Minimizing Data Movement Using Distant Futures" at the research poster session at Supercomputing 2023:


Futures are a widely used concept for organizing concurrent computations. A Future is a variable that represents the result of a function call whose computation may still be pending. When evaluated, the future blocks (if needed) until the result becomes available. This allows for the easy construction of highly parallel programs.
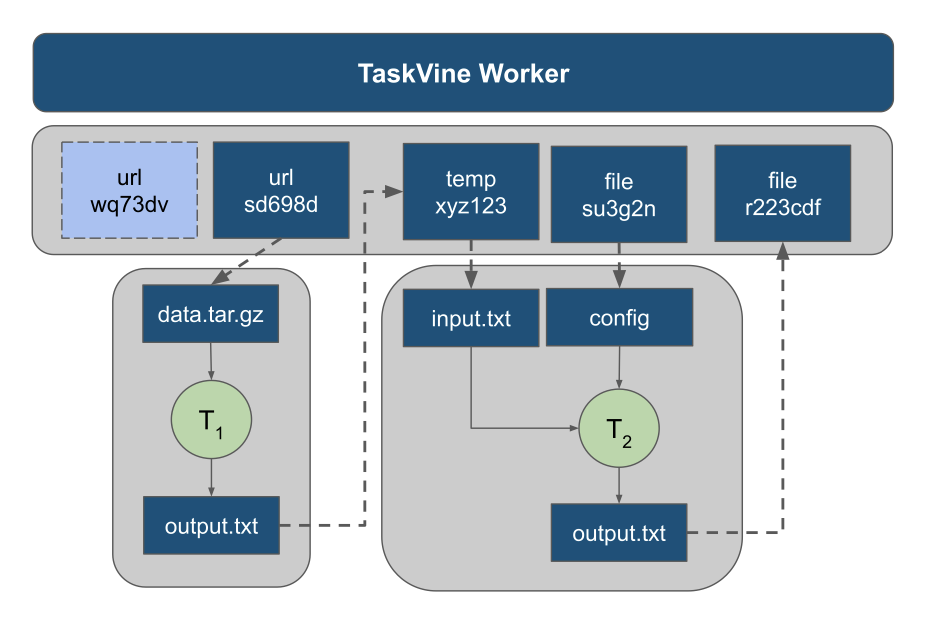
Barry developed a future based execution model for the TaskVine workflow execution system. This allows one to submit and chain function calls written in plain Python. TaskVine then schedules the tasks throughout the cluster, providing a variety of data management services.

However, at very large scales, a natural bottleneck is the return of computed values back to the original manager. To overcome this, we introduce the notion of Distant Futures in which a value is not only pending in time, but potentially left in the cluster on a remote node. Tasks requiring this value can then be scheduled to the same node, or to transfer the value within the cluster, rather than bringing it back home.
Combining distant futures with asynchronous transfer provides significant benefits for applications that are bottlenecked in data transfer, as our results show:

- Barry Sly-Delgado and Douglas Thain, Poster: Minimizing Data Movement Using Distant Futures ACM/IEEE Supercomputing, November, 2023.