Barry Sly-Delgado presented our paper titled: "Reshaping High Energy Physics Applications for Near-Interactive Execution Using TaskVine" at the 2024 Supercomputing Conference in Atlanta, Georgia. This paper investigates the necessary steps to convert long-running high-throughput high energy physics applications to high concurrency. This included incorporating new functionality within TaskVine. The paper presents the speedup gained as changes were incorporated to the workflow execution stack for application DV3. We eventually achieve a speedup of 13X.
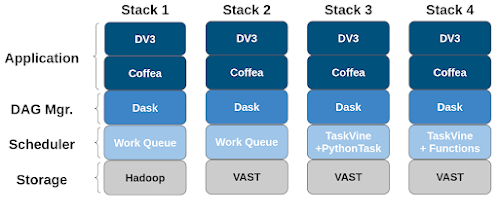
Configurations for each workflow execution stack as improvements were made.
Starting with stack 1. The first change incorporated was to the storage system where initial data sets are stored. This change showed little improvement, taking 3545s runtime to 3378s. This change is minimal as much of the data handling during application execution is related to intermediate results. Initially, with stack 1 and 2, intermediate data movement is handled via a centralized manager.
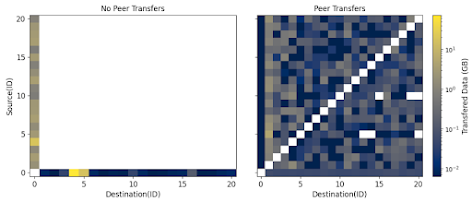
data movement during application execution between Work Queue and TaskVine. With TaskVine, the most data exchanged between any two nodes tops off around 4GB (the manger is node 0). With Work Queue the most data transferred is 40GB
Incorporated in stack 3 is a change of scheduler, TaskVine. Here, TaskVine allows for intermediate results to be stored on node-local storage and transferred between peer compute nodes. This relieves strain on the centralized manager and allows it to schedule tasks more effectively. This change drops the runtime to 730s.
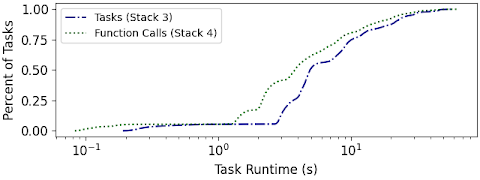
CDF of task runtimes within the application per execution paradigm. With Function Calls, individual tasks execute faster.
Our final improvement changes the previous task execution paradigm within TaskVine. Initially "PythonTasks" serialized functions along with arguments and distributed them to compute nodes to execute individual tasks. Under this paradigm, the python interpreter would be invoked for each individual task. Our new task execution paradigm, "Function Calls" stands up a persistent Python process, "Library Task", that contains function definitions that can be invoked via individual function calls. Thus, invocations of the Python interpreter are reduced from per-task to per-compute-node. This change reduces runtime to 272s for a 13X speedup from our initial configuration.
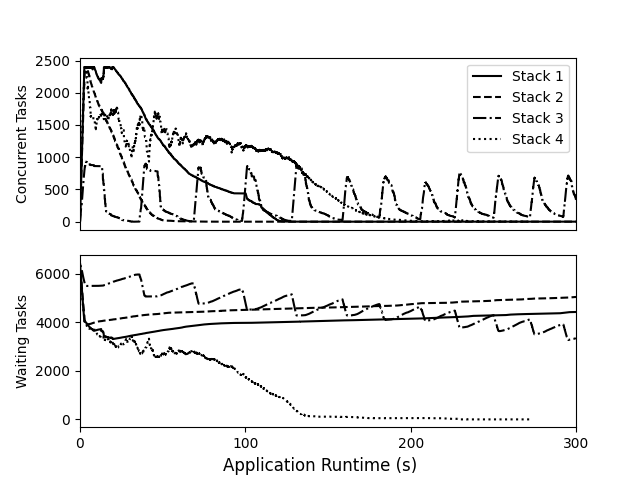
Application execution comparison between stack configurations.


