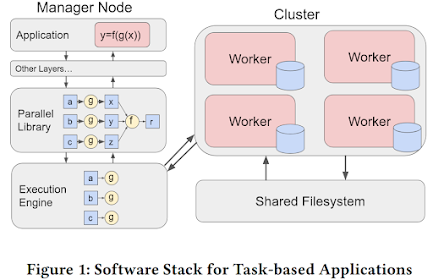
Modern applications are increasingly being written in high-level programming languages (e.g., Python) via popular parallel frameworks (e.g., Parsl, TaskVine, Ray) as they help users quickly translate an experiment or idea into working code that is easily executable and parallelizable on HPC clusters or supercomputers. Figure 1 shows the typical software stack of these frameworks, where users wrap computations into functions, which are sent to and managed by a parallel library as a DAG of tasks, and these tasks eventually are scheduled by an execution engine to execute on a remote worker node.
A traditional way to execute functions remotely is to translate them into executable tasks by serializing functions and their associated arguments into input files, such that these functions and arguments are later reconstructed on remote nodes for execution. While this way fits function-centric applications naturally into well understood task-based workflow systems, it brings a hefty penalty to short-running functions. A function now takes extra time for its states to be sent and reconstructed on a remote node which are then unnecessarily destroyed at the end of that function’s execution.
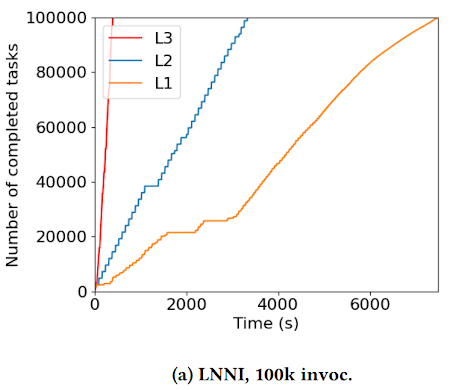
At HPDC 2024, graduate students Thanh Son Phung and Colin Thomas proposed the idea that function contexts, or states, should be decoupled from function’s actual execution code. This removes the overhead of repeatedly sending and reconstructing a function’s state for execution, and allows functions of the same type to share the same context. The rest of the work then addresses how a workflow system can treat a function as a first-class citizen by discovering, distributing, and retaining such context from a function. Figure below shows the execution time of the Large-Scale Neural Network Inference application, totaling 1.6 million inferences separated into 100k tasks, with increasing levels of context sharing (L1 is no sharing, L3 is maximum sharing). Decoupling the inference function’s context from the inference massively reduces the execution time of the entire workflow by 94.5%, from around 2 hours to approximately 7 minutes.
An interested reader can find more details about this work in the paper:Thanh Son Phung, Colin Thomas, Logan Ward, Kyle Chard, and Douglas Thain. 2024. Accelerating Function-Centric Applications by Discovering, Distributing, and Retaining Reusable Context in Workflow Systems. In Proceedings of the 33rd International Symposium on High-Performance Parallel and Distributed Computing (HPDC '24). Association for Computing Machinery, New York, NY, USA, 122–134. https://doi.org/10.1145/3625549.3658663