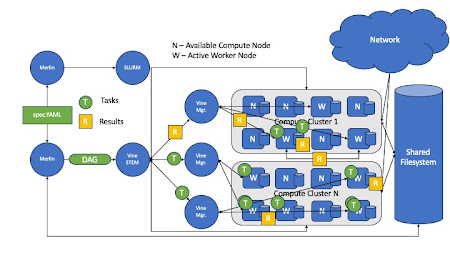
On September 26-27 members of the CCL team attended ParslFest 2024 in Chicago, Illinois to speak about TaskVine and connect with our ongoing collaborators at the Parsl Project.
Grad student Colin Thomas delivered a talk titled "Parsl/TaskVine: Interactions between DAG Manager and Workflow Executor."
The talk highlighted recent developments in the implementation of TaskVine Temporary Files within the Parsl/TaskVine Executor. Temporary files allow users to express intermediate data in their workflows. Intermediate data are items produced by tasks, and consumed by tasks. With the use of TaskVine Temporary Files, this intermediate data will remain in the cluster for the duration of a workflow. Keeping this data in the cluster can benefit a workflow that produces intermediate files of considerable quantity or size. 
In addition to adding temporary files to the Parsl/TaskVine executor, the talk presented ongoing work on the development of intermediate data-based "task-grouping" in TaskVine and extending it to the TaskVine executor. The concept of grouping related tasks may sound familiar to Pegasus users or other pre-compiled DAG workflow systems. Currently task-grouping is focused on scheduling sequences of tasks which contain intermediate dependencies. The desired outcome is for TaskVine to interpret pieces of the DAG to identify series of sequentially-dependent tasks in order to schedule them on the same worker, such that intermediate data does not need to travel to another host. Extending this capability to Parsl brought about an interesting challenge which questioned the relationship between DAG manager and executor.
The problem is that in the typical workflow executor scheme, such as with Parsl or Dask, the executor will receive tasks from the DAG manager only when they are ready to run. In order for TaskVine to identify sequentially dependent tasks it needs to receive tasks which are future dependencies of those that are ready to run.
The solution to this came about as a special implementation of a Data Staging Provider in Parsl, which is the mechanism for determining whether data dependencies are met. When the TaskVine staging provider encounters temporary files, it will lie to the Parsl DFK (Data Flow Kernel) in saying the file exists. Therefore Parsl will send all temporary-dependent tasks to TaskVine without waiting for the files to actually materialize. This offers TaskVine relevant pieces of the DAG to inspect and identify dependent sequences.

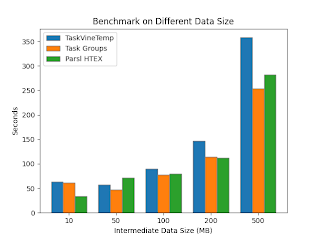
The impact of task grouping was evaluated on a benchmark application. Each benchmark run consists of 20 task sequences of variable length. Each task in a sequence produces and consumes an intermediate file of variable size. The effect on running time is shown while adjusting these parameters. Grouping tasks was shown to benefit the performance across a variety of sequence lengths, and when intermediate data size exceeds 500MB.
In addition to the positive benchmark results, this talk promoted discussion about this non-traditional interaction between DAG manager and executor. The DAG manager has insight into future tasks and their dependencies. The executor possesses knowledge about data locality. Combining this information to make better scheduling decisions proved to have some utility, yet it challenged the typical scheme of communication between Parsl and the TaskVine executor.