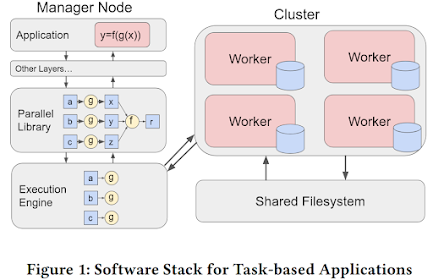
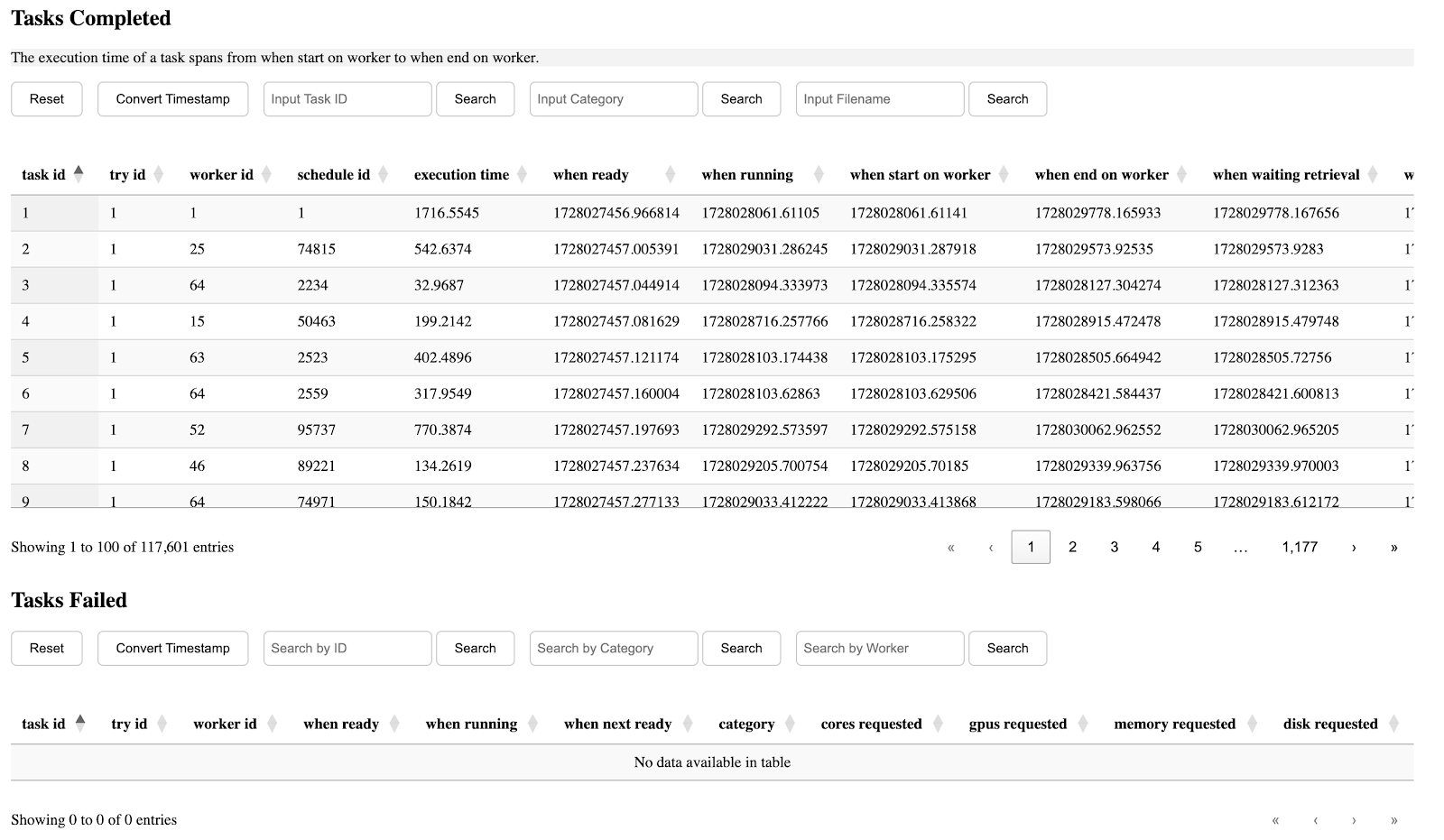
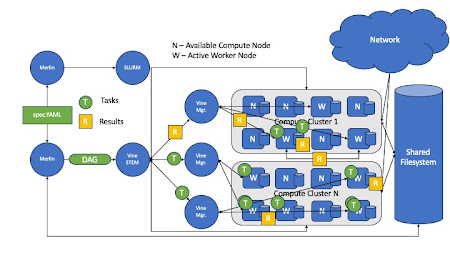
In our recent work, we introduced a file pruning technique into DaskVine to address challenges in managing intermediate files in DAG-based task graphs. This technique systematically identifies and removes intermediate stale files—those no longer needed by downstream tasks—directly from worker nodes. By freeing up storage in real time, file pruning not only enables workers to process more computational tasks with limited disk space but also makes applications feasible that were previously constrained by storage limitations.
Specifically, the pruning algorithm monitors task execution in the graph, categorizing tasks as waiting or completed. Once a task finishes, it prunes its parent tasks’ output files if all dependent child tasks are done and immediately submits dependent tasks for execution when their inputs are ready.
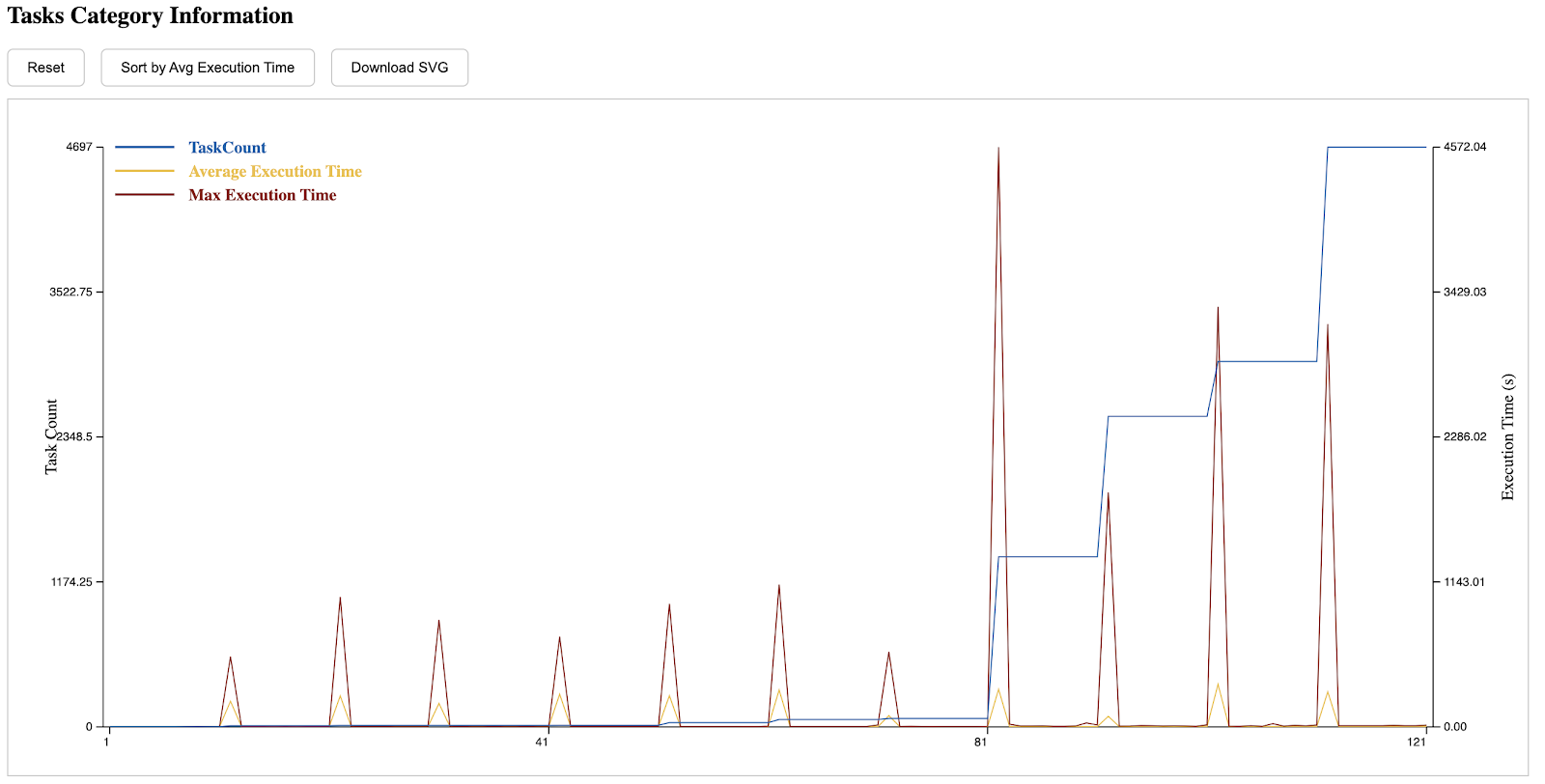
To evaluate the effectiveness of our file pruning technique, we utilized four key metrics:
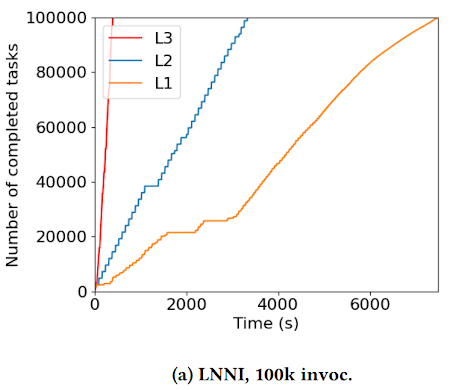
File Retention Rate (FRR): FRR represents the ratio of a file's retention time on storage to the total workflow execution time. It indicates how long files remain in storage relative to the workflow's progress. A shorter FRR reflects more efficient pruning. The following figures show the FRR over all intermediate files, each producing by one specific task. The left graph (FCFS) shows higher and more uniform FRR, where files remain on storage for a significant portion of the workflow. In contrast, the right graph (FCFS with Pruning) shows a clear reduction in FRR for most files, which proves that pruning reduces storage usage by removing stale files promptly.

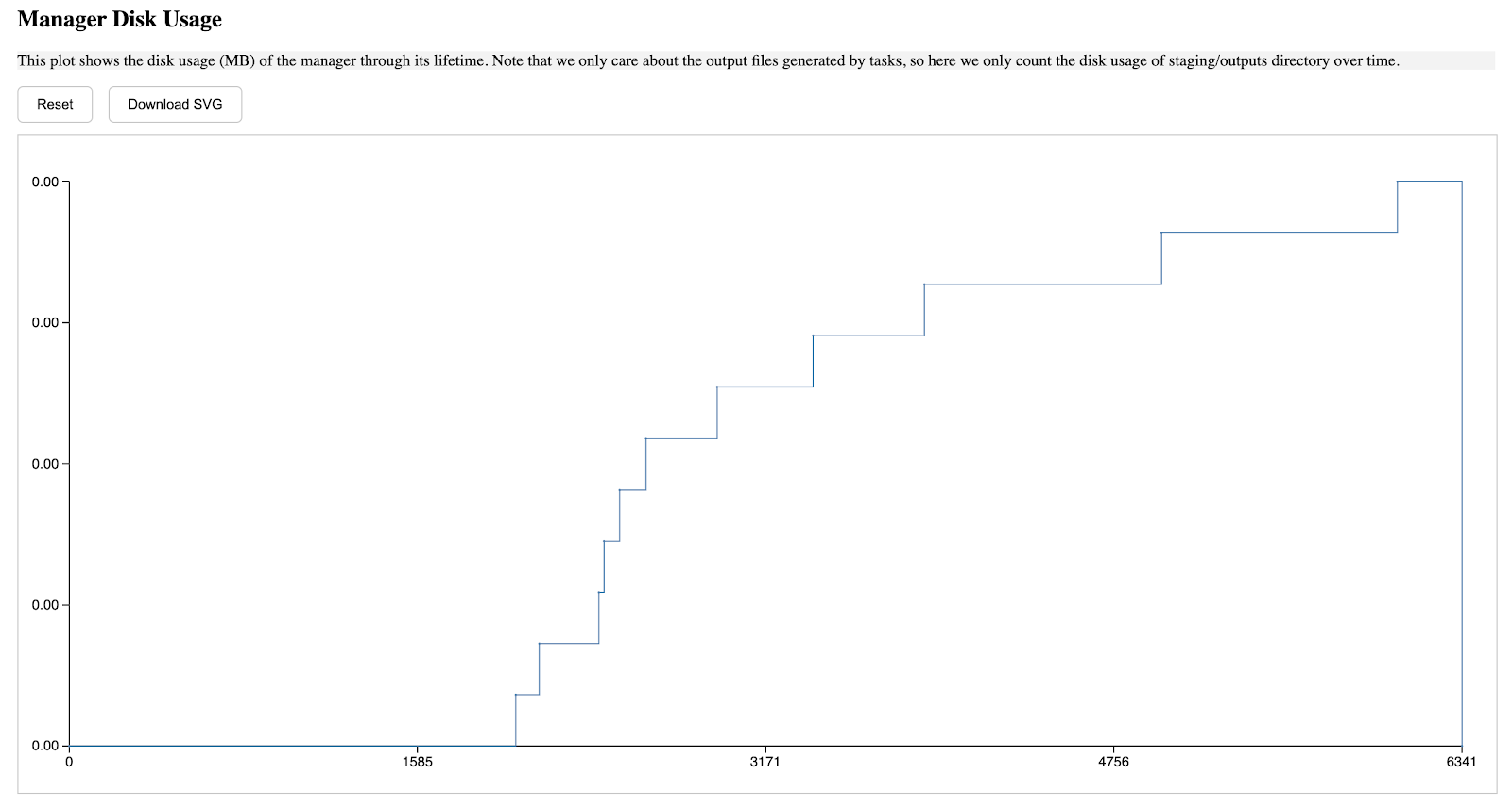
Accumulated Storage Consumption (ASC) and Accumulated File Count (AFC): ASC measures the total amount of storage consumed across all worker nodes throughout the workflow execution, while AFC tracks the total number of files retained across all worker nodes during the workflow. In the following, the left graph shows that both ASC and AFC steadily increase throughout the workflow, peaking at 1082.94 GB and 299,787 files, respectively. This highlights significant storage pressure without pruning. The right graph demonstrates dramatic reductions, with peaks at 326.78 GB for ASC and 80,239 files for AFC. This confirms that pruning effectively reduces storage consumption and file count by promptly removing unnecessary intermediate files.

Worker Storage Consumption (WSC): WSC reflects the storage consumption of individual workers at any point during the workflow execution. It helps assess the balance of storage usage among workers. The left graph shows a peak WSC of 24.95 GB, indicating high storage pressure on individual workers. In contrast, the right graph shows a significantly lower peak of 7.07 GB, demonstrating that pruning effectively reduces storage usage per worker and balances the load across the cluster.